Generative pre-trained models have demonstrated remarkable effectiveness in language and vision domains by learning useful representations.
In this paper, we extend the scope of this effectiveness by showing that visual robot manipulation can significantly benefit from large-scale video generative pre-training.
We introduce GR-1, a straightforward GPT-style model designed for multi-task language-conditioned visual robot manipulation.
GR-1 takes as inputs a language instruction, a sequence of observation images, and a sequence of robot states.
It predicts robot actions as well as future images in an end-to-end manner .
Thanks to a flexible design, GR-1 can be seamlessly finetuned on robot data after pre-trained on a large-scale video dataset.
We provide inaugural evidence that a unified GPT-style transformer, augmented with large-scale video generative pre-training, exhibits remarkable generalization to multi-task visual robot manipulation.
Method
GR-1 is first pre-trained on the task of video prediction with a large-scale video dataset.
It is then finetuned on robot data to learn multi-task visual robot manipulation.
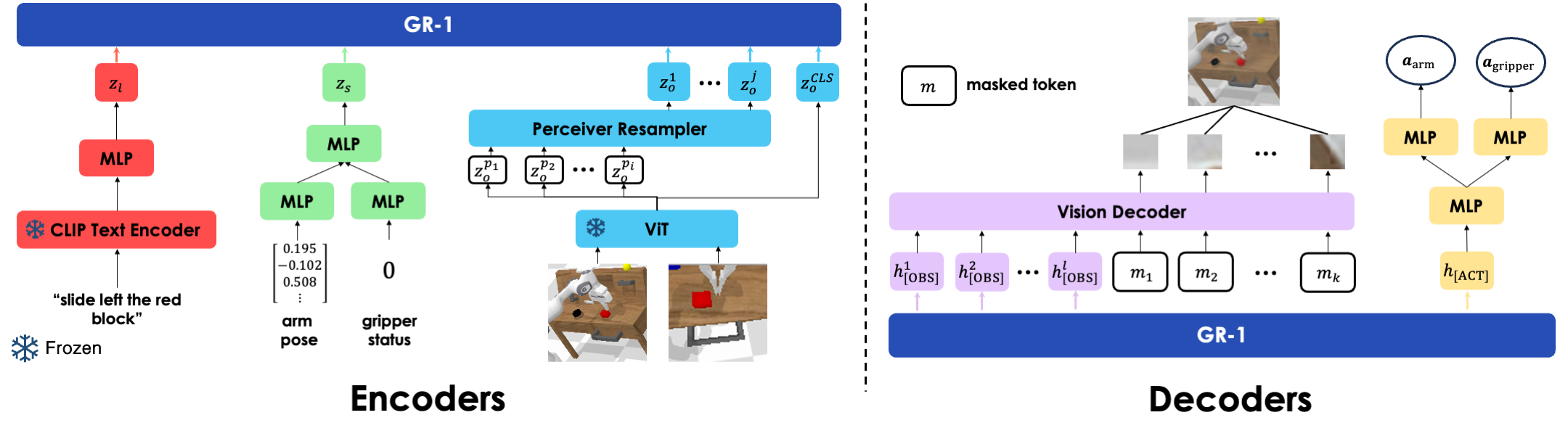
GR-1 is a simple GPT-style transformer which is able to take different modalities as inputs and outputs future images and actions.
The language input is encoded via CLIP text encoder.
Visual inputs are encoded via a vision transformer which has been pretrained with MAE.
A perceiver resampler is used to reduce the token number.
Robot states, which contains the 6D pose of the robot end-effector and a binary status of the gripper, are encoded via linear layers.
Before being fed into the causal transformer, the embeddings of all modalities are passed through linear layers to align the dimension.
Future images are predicted with a transformer decoder consisting of self-attention blocks and MLPs.
Arm and gripper actions are predicted via linear layers.
More details can be found in the paper.
Real Robot Experiments
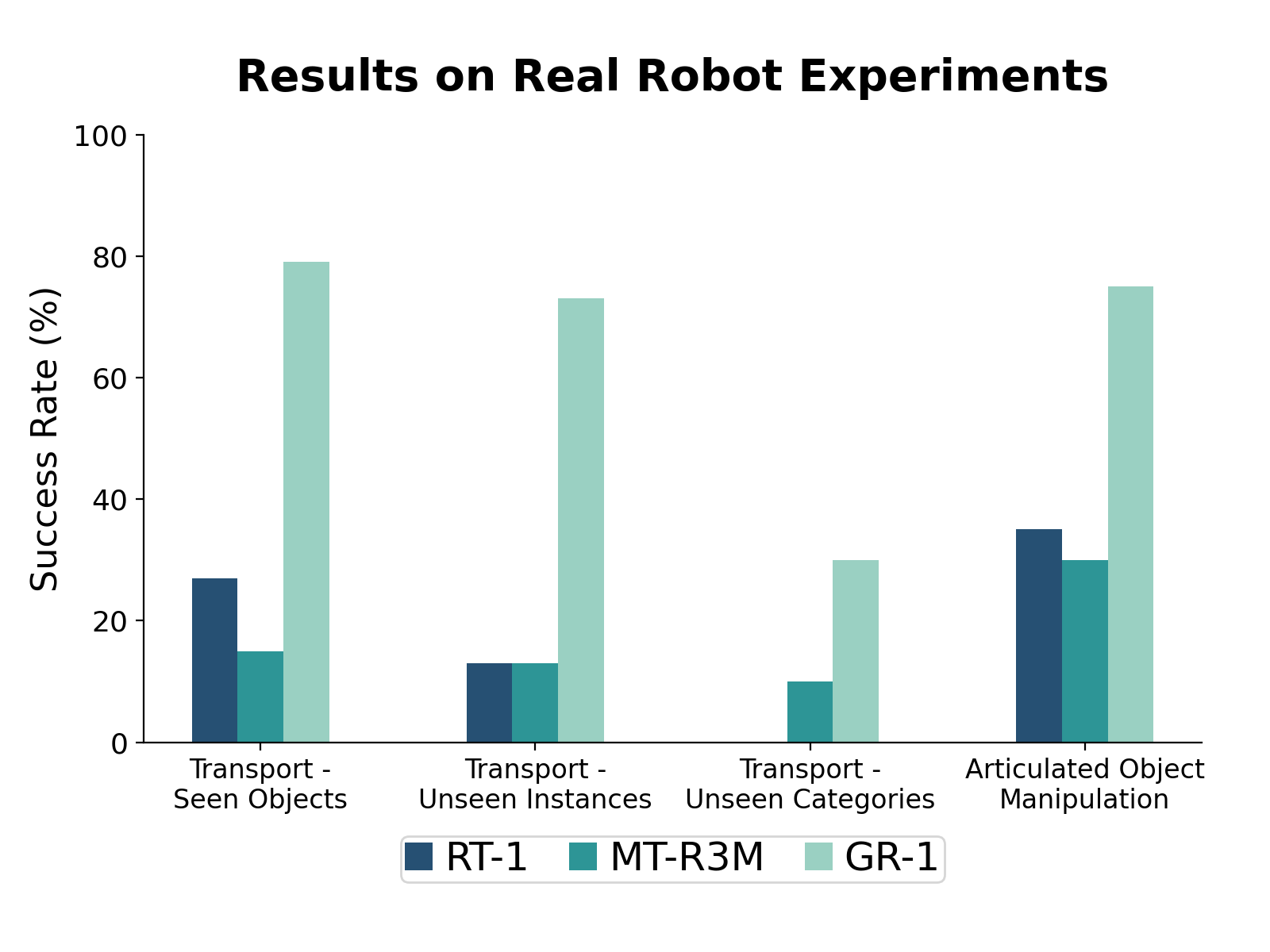
We perform extensive end-to-end real robot experiments to evaluate how GR-1 works in the real world.
We first evaluate on object transportation in three settings: Seen Objects, Unseen Instances (unseen object instances of seen categories), and Unseen Categories (unseen objects of unseen categories).
Example instructions include "put the broccoli onto the plate".
This task is challenging as the robot needs to ground the correct object in the scene and successfully grasp and place it in the correct area.
We also perform experiments on contact-rich articulated object manipulation.
Example instructions include "open the drawer".
Results are shown in the below figure.
1. Seen Objects
In this setting, there are three objects, i.e. a broccoli, an eggplant, and a bell pepper.
The robot is trained to perform transporting one of the three objects from the plate to the table or vice versa.
We evaluate the performance on transporting these three objects in 1) training scenes 2) scenes with distrators and 3) scenes with background changes and distrators.
In the scenes with distractors, we introduce three unseen objects, i.e. a corn, a tomato, and a yellow peach.
In the scenes with background changes and distrators, we futher add a wooden board and an unseen bowl.
GR-1 outperforms comparing baseline methods and achieve a high success rate in this setting.
2. Unseen Instances & Unseen Categories
In these two settings, we challenge the robot to transport unseen objects.
There are five objects in the scene, i.e. a broccoli, an eggplant, a bell pepper, a yellow peach and a tomato.
While "broccoli", "eggplant", and "bell peper" are seen in the languages during finetuning, these three instances are unseen in the robot training data.
In Unseen Instances, we command the robot to transport these three instances.
Both "yellow peach" and "tomato" are unseen in the languages of the robot training data.
In Unseen Categories, the robot is instructed to transport these two objects.
The performance of GR-1 drops when evaluted on unseen objects.
However, it is surprising that the drop for Unseen Instances is modest.
This demostrate GR-1 possesses strong zero-shot generalization to unseen instances.
In the most challenging setting of unseen categories, a typical failure mode is that GR-1 sometimes mixes up the bell pepper with the peach which has a similar color.
3. Articulated Object Manipulation
In this experiment, we aim to evaluate GR-1 on handling contact-rich articulated object manipulation.
We train GR-1 to open and close a drawer.
GR-1 outperforms the comparing baseline methods.
Typical failure modes of GR-1 include 1) failing to completely close the drawer in the closing task and 2) failing to engage with the drawer handle when pulling it out in the opening task.
CALVIN Benchmark Experiments
CALVIN is a challenging benchmark focusing on learning language-conditioned policy for long-horizon robot manipulation.
It contains 34 manipulation tasks and features unconstrained language instructions.
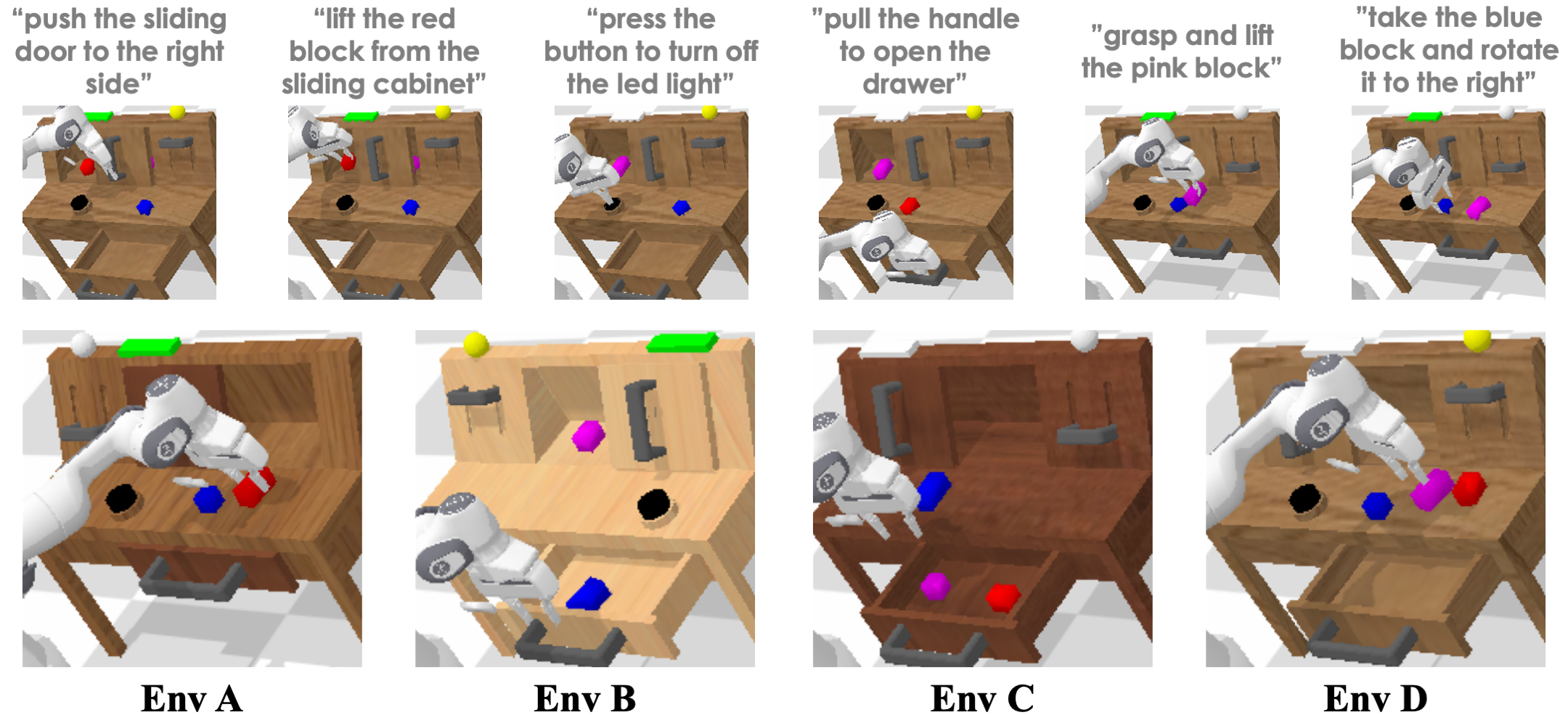
The environment contains a Franka Emika Panda robot with a parallel-jaw gripper and a desk with a sliding door, a drawer that can be opened or closed, blocks with different colors, an LED, and a light bulb that can be turned on or off.
CALVIN contains 4 different environments A, B, C, and D.
These four environments are different in desk colors and object configurations.
We perform experiments on CALVIN in four settings.
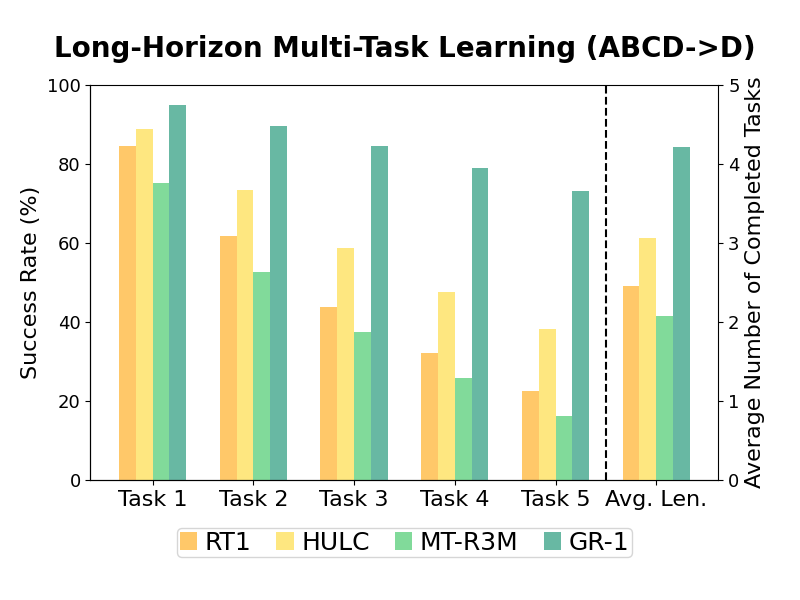
1. Long-Horizon Multi-Task Learning (ABCD->D)
In this setting, the robot is trained with data collected from environments A, B, C, and D and evaluated in environment D.
During the evaluation, the robot aims to continuously solve up to 5 tasks by understanding a series of 5 language instructions in a row.
The robot receives the next task only if the current one is successfully completed.
GR-1 outperforms baseline methods in task success rates.
In particular, it improves the success rate of completing 5 tasks in a row from 38.3% to 73.1%.
Average length is the average number of completed task in a row of 5.
GR-1 improves average length from 3.06 to 4.21, showing strong long-horizon multi-tasking capability.
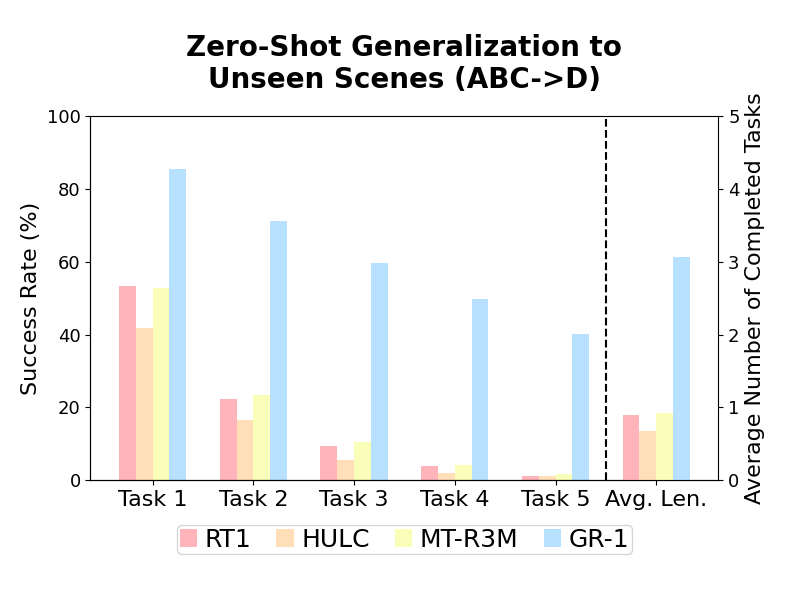
2. Zero-Shot Generalization to Unseen Scenes (ABC->D)
In this setting, the robot is trained with data collected from environment A, B, and C and evaluated in environment D, which is unseen during training.
The robot needs to understand semantic information from the data collected in environment A, B, and C and generalize them to environment D.
GR-1 outperforms baseline methods by a large margin.
We hypothesize that the strong generalization capability stems from being exposed to large-scale data in pre-training.
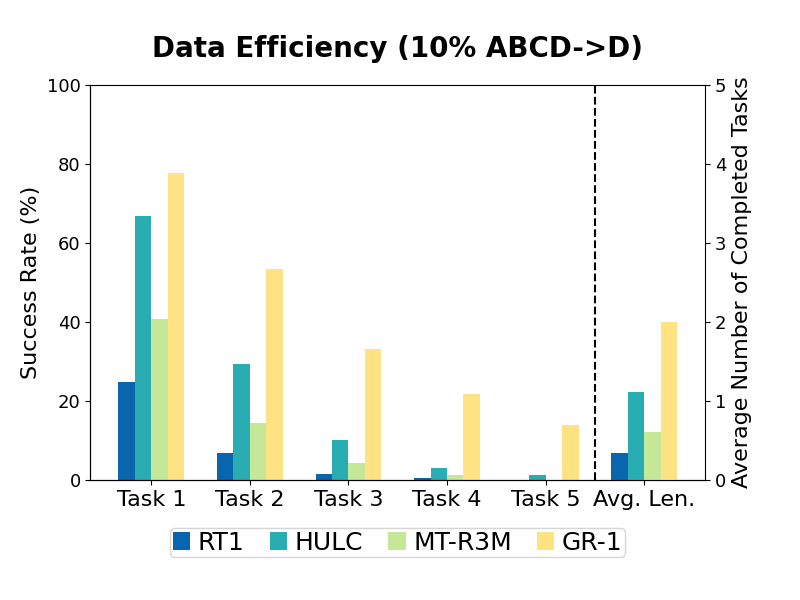
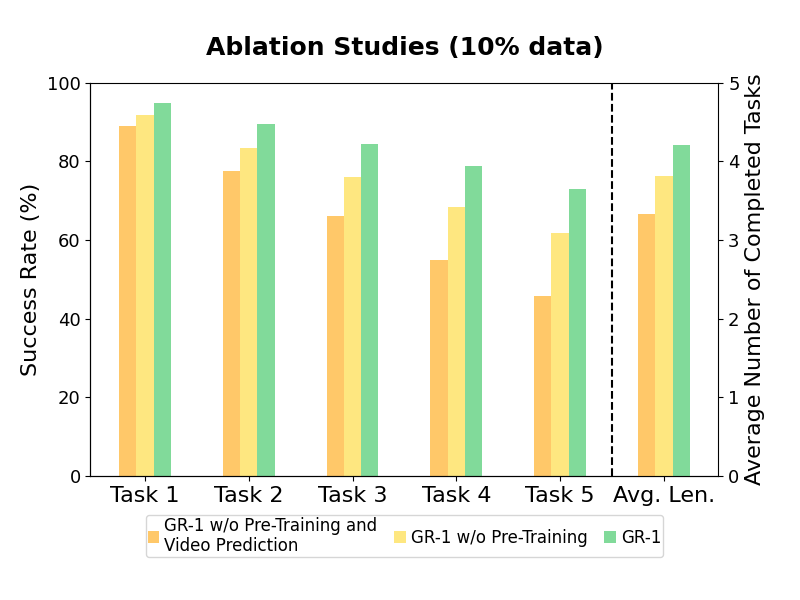
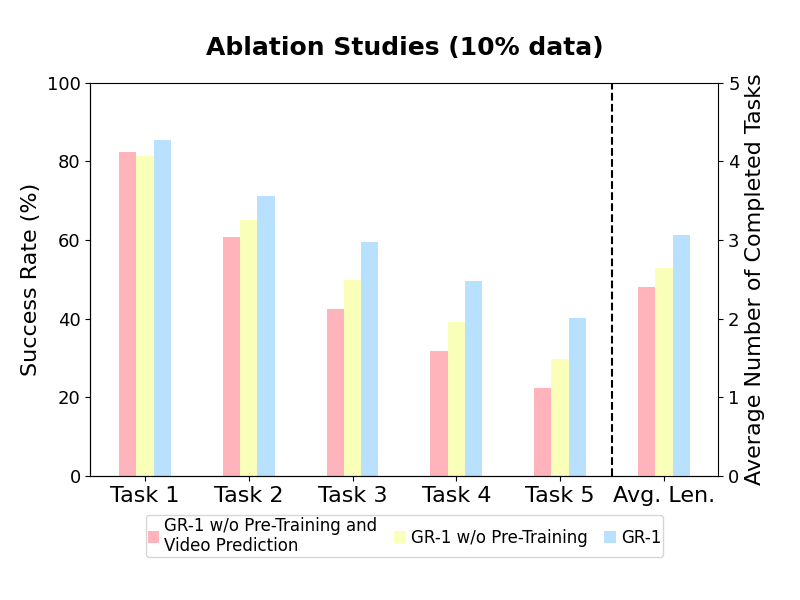
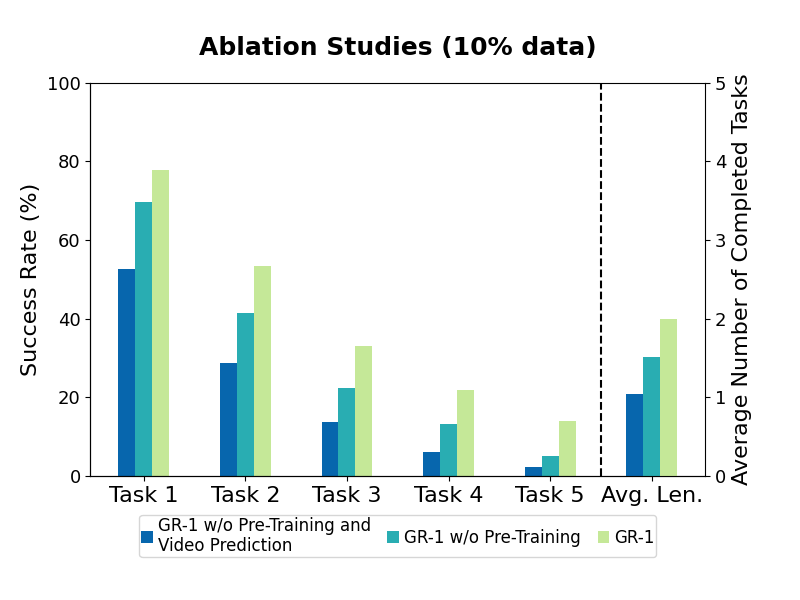
3. Data Efficiency (10% ABCD->D)
Robot data is sparse.
We want to understand how GR-1 performs when given a small amount of data.
We sampled about 10% data from the training data of the ABCD->D split for training.
Specifically, we sampled 66 trajectories for each of the 34 tasks, i.e. 2244 trajectories in total (ABCD->D split contains 22966 training trajectories).
The performance of all methods degrades.
We compare the success rate of each task when trained on the 10% data and the full data.
The success rates of tasks involving block manipulation decreases the most.
These tasks are difficult because the robot needs to first grasp the correct block and then manipulate it according to the language instruction.
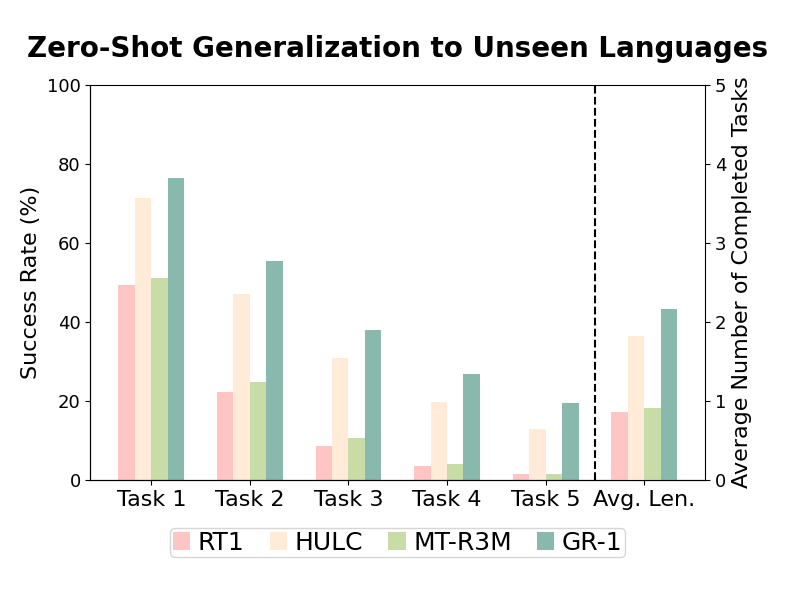
4. Zero-Shot Generalization to Unseen Languages
Human languages are diverse, i.e. there are different ways of describing a task.
We aim to test whether GR-1 is able to generalize to languages that are different from those seen in training.
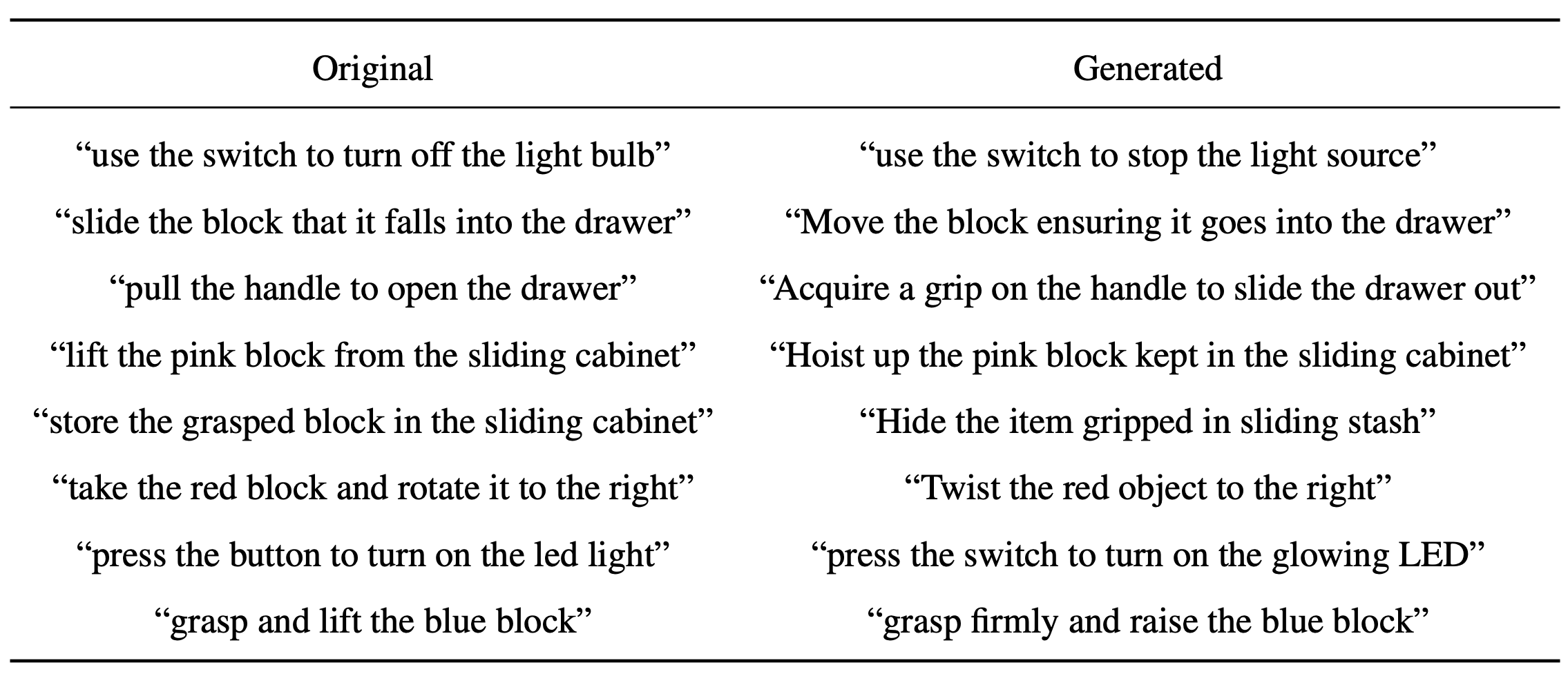
We leveraged GPT-4 to generate synonymous instructions for each of the 34 tasks and used these unseen language instructions for evaluation.
Examples of generated languages can be found in the below figure.
GR-1 is able to generalize to unseen languages with a high success rate.
We hypothesize this generalization capability attributes to being exposed to diverse languages in the large video dataset during pre-training and freezing the strong CLIP text encoder during the whole training process.
Ablation Studies and Video Prediction Results
GR-1 features video prediction and large-scale pretraining on video prediction.
We perform ablation studies to study how these two factors influence the performance.
GR-1 outperforms the variant without pre-training and the variant without pre-training and video prediction in all experiments.
We hypothesize that this is because the large-scale video pre-training helps GR-1 learn an accurate video prediction model which helps the robot understand what shall happen in future steps given the language instruction and previous observations.
And this information acts as a strong signpost for the robot to generate pertinent actions for rolling out trajectories.
Without pre-training, the video prediction of GR-1 w/o Video Pre-training may not be as robust.
We probe into GR-1 to investigate its video prediction performance on CALVIN and real robot data.
Results are shown in the below figure in which the images in the green boxes are the ground-truth images and those in the blue boxes are the predicted images.
GR-1 is able to reconstruct future frames correctly on both CALVIN data and real robot data, although some details (e.g. occluded objects) are missing.
This video prediction signal can serve as a strong guide for action predictions.
More results can be found in the paper.
Conclusions and Future Work
In this paper, we propose to leverage large-scale video generative pre-training for enhancing visual robot manipulation learning.
We present GR-1, a strightforward GPT-style transformer that takes as input a language instruction, a sequence of observation images and robot states, and outputs actions and future images in an end-to-end manner.
GR-1 is first pre-trained on language-conditioned video prediction with a large-scale video dataset.
Owing to a flexible design, it can then be seamlessly finetuned on robot data to predict actions and future frames.
GR-1 shows strong performance in both simulation and real robot experiments.
By incorporating large-scale video data, we showcase that GR-1 is able to perform robustly in scenes which are disturbed heavily from those in the training data.
More importantly, GR-1 is able to generalize to unseen object instances and categories in a zero-shot manner.
In the future, we hope to incorporate more video data in training to further enhance the robustness and generalization capability of GR-1.
In addition, we plan to scale up the robot data by increasing both the number of robot trajectories in diverse environments and the number of manipulation skills.
BibTeX
@misc{wu2023unleashing,
title={Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation},
author={Hongtao Wu and Ya Jing and Chilam Cheang and Guangzeng Chen and Jiafeng Xu and Xinghang Li and Minghuan Liu and Hang Li and Tao Kong},
year={2023},
eprint={2312.13139},
archivePrefix={arXiv},
primaryClass={cs.RO}}